




Over the last 9 months, rapid advancements in Generative AI have impacted nearly every industry. What are the implications for how we do observability and monitoring of our production systems?
I posit that the next evolution in this space will be a new class of solutions that do "Inferencing" - i.e., directly root-cause the source of an error for a developer with reasonable accuracy.
In this article, we examine -
Inferencing as a natural next step to observability
Learnings from AIOps - why it failed to take off, and implications for inferencing
Some emergent principles for the class of inferencing solutions
Where we are
To understand the next generation of observability, let us start with the underlying goal of all of these tools. It is to keep production systems healthy and running as expected and, if anything goes wrong, to allow us to quickly understand why and resolve the issue.
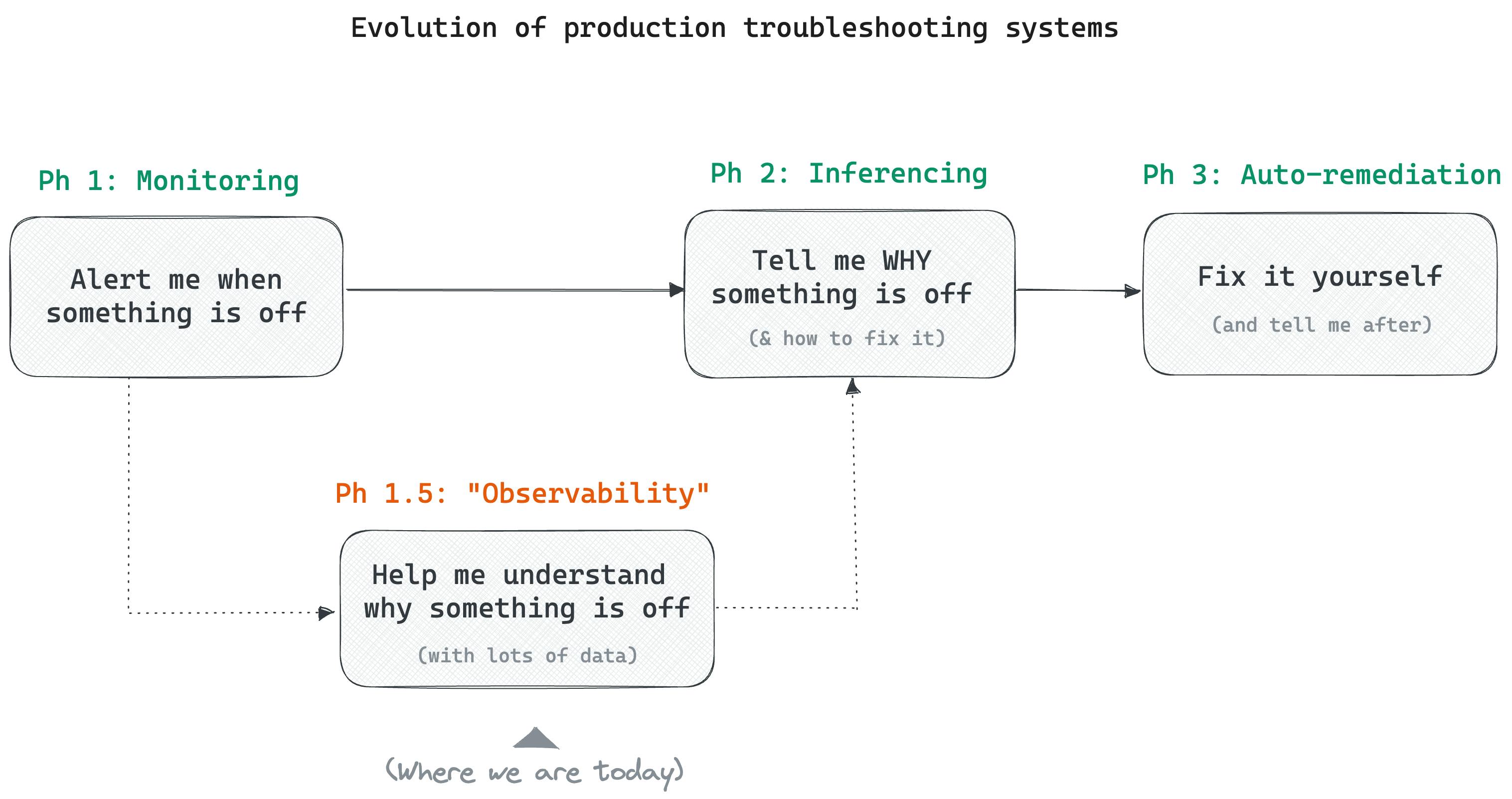
If we start there, we see that are three distinct levels in how tools can support us:
Level 1: "Alert me when something is off in my system" — monitoring
Level 2: "Tell me why something is off (and how to fix it)" — let's call this inferencing
Level 3: "Fix it yourself and tell me what you did" — auto-remediation.
Monitoring tools do Level 1 (detecting issues) reasonably well. The natural next step is level 2, where a system automatically tells us why something is breaking. We don't yet have solutions that can do this, so we added a category of tools called observability between Level 1 and Level 2, whose goal was to "help us understand why something is breaking”. This essentially became "any data that could potentially help us understand what is happening".
The problem with observability today
The main problem with observability today is that it is loosely defined and executed. This is because we don't know what data we need beforehand - that depends on the issue. And the nature of production errors is that they are long-tail and unexpected - if they could've been predicted, they would've been resolved. So we collect a broad variety of data types - metrics, logs, distributed traces, stack-traces, error data, K8s events, and continuous profiling - all to ensure we have some visibility when things go wrong.
The best way to understand observability as it is implemented in practice is - "Everything outside of metrics, plus metrics."

An observability platform also has to make choices around how much data to capture and store. This decision is currently pushed to customers, and customers default to collecting as much data as they can afford to. Rapid cloud adoption & of SaaS models has made it possible to collect and store massive amounts of data.
The underlying human driver for collecting more types & volume of observability data is - "What if something breaks and I don't have enough data to be able to troubleshoot?" This is every engineering team's worst nightmare. As a result of this, we have a situation today where there is -
Observability data types are continuously expanding
Observability data volumes are exploding
Increasing tool sprawl - avg. company uses 5+ observability tools
With all this, we started running into new problems. It is now increasingly hard for developers to manually navigate the tens of data-intensive dashboards to identify an error. Observability has also become prohibitively expensive, so companies have to start making complex trade-offs around what data to store, sometimes losing visibility. Between both of this and the continued increase in complexity of production systems, we are seeing that MTTR for production errors is actually increasing over the years.
Inferencing— observability plus AI
I'd argue the next step after observability is Inferencing — where a platform can reasonably explain why an error occurred, so we can fix it. This becomes possible now in 2023 with the rapid evolution of AI models in the last few months.
Imagine a solution that:
Automatically surfaces just the errors that need immediate developer attention.
Tells the developer exactly what is causing the issue and where the issue is - this pod, this server, this code path, this type of request.
Guides the developer on how to fix it.
Uses the developer's actual actions to continuously improve its recommendations.
There is some early activity in this space (including ZeroK.ai), but we are still extremely early and we can expect several new companies to emerge here over the next couple of years.
However, any conversation around AI + observability would be incomplete without a discussion on AIOPs, which was the same promise (use AI to automate production ops), and saw a wave of investment between '15-20 but had limited success and died down. For a comprehensive exploration of why AIOPs failed, read this - AIOps Is Dead.
Avoiding the pitfalls of AIOps
The original premise of AIOps was that if we pushed data from the five or six different observability sources into one unifying platform and then applied AI on all this data (metrics, logs, dependencies, traces, configurations, updates, K8s events), we would get to insights on why something broke.
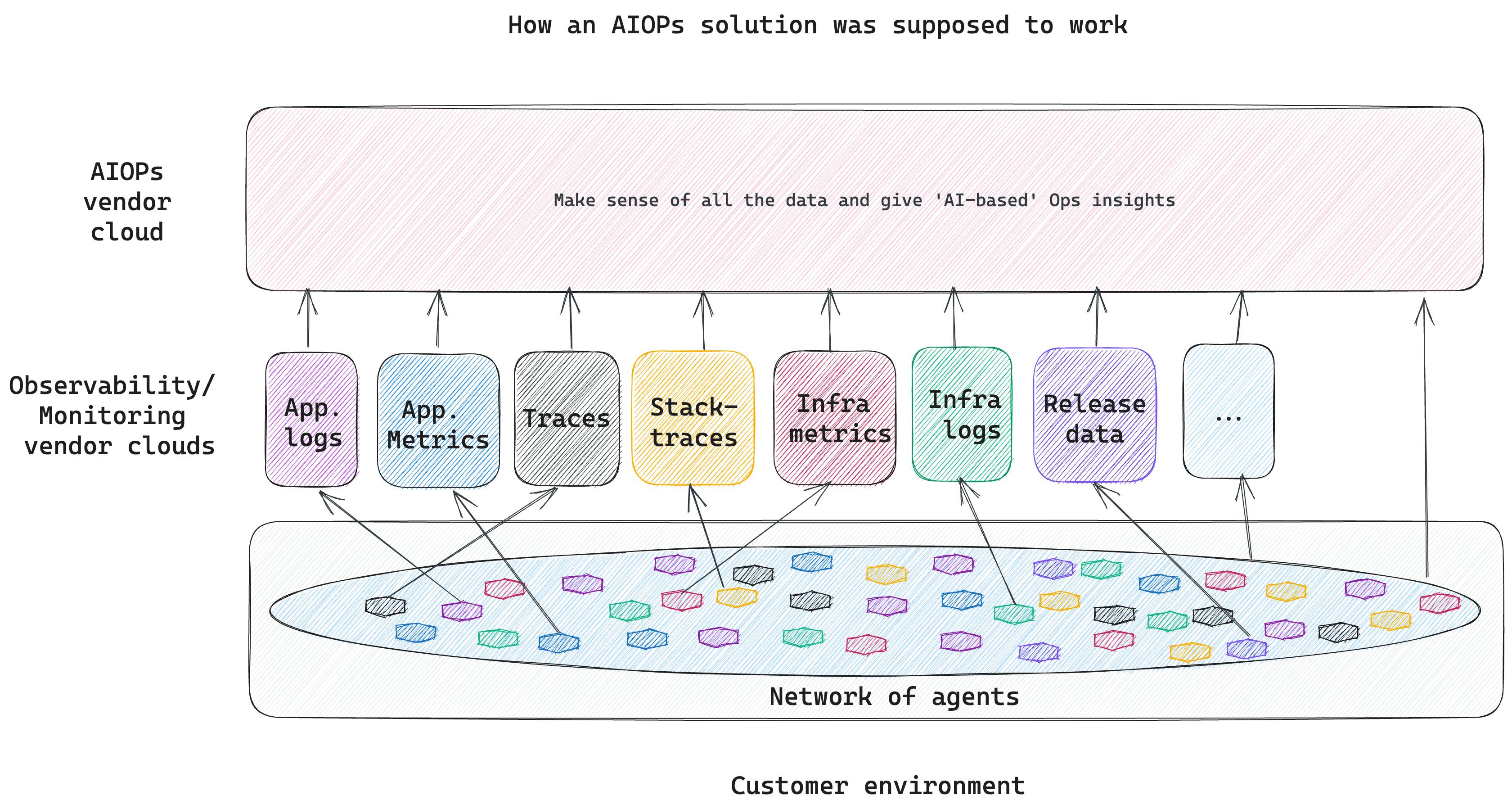
While attractive in theory, this argument fell short in a few ways.
First, tying everything together was impractical and a much harder problem than estimated. Different observability tools collected different data about different systems at different time intervals, and they exposed different subsets of the data they collected to a third-party tool. In addition, each individual customer had their own data collection practices. Enterprises, for example, would have several different observability tools with highly customized and non-standard data collection, and the enterprise would have to manually provide context about them to any new AIOPs tool. All this impacted the quality of response/ root-causing that the ML models could get to and the value they ended up delivering.
Second, the AIOPs model was too broad and not use-case driven. For example, what specific kinds of errors were the models targeting? Infrastructure errors/ code errors/ hard errors/ soft errors? Most AIOPs platforms went quite broad here, and tried to ingest 8 different data types in the hope of finding patterns and anomalies, and had too much dependence on how much data and of what quality the customer pushed into the platform, which varied the quality of their output.
Third, the integration process in each company was too complex. A large company has a fragmented footprint of observability tools, with 10s of tools being run by different teams. An AIOps platform needed to be integrated into all those tools to be able to add value. Even in the case of the AIOPs module of a large observability platform like a Datadog or DynaTrace, the requirement was that the entire observability stack be moved to the single vendor (across infra & app. metrics, logs, distributed tracing, error monitoring, and so on), for the AIOPs module to be effective.
Fourth, the massive data volumes and the processing power required to process the data also made these tools very expensive in relation to their questionable value.
All this resulted in a degree of disillusionment among many early adopters of AIOps tools, and most companies reverted to a simple “collect data and display on dashboards” mechanism for their needs.
Several learnings from here will be applicable and can learn and apply as we attempt Inferencing.
Principles of Inferencing
Inferencing would have to be different in a few ways to more efficiently achieve the end goal.
Architected from the ground up with AI in mind
An Inferencing solution would have to be architected ground-up for the AI use-case i.e., data collection, processing, pipeline, storage, and user interface are all designed ground-up for "root-causing issues using AI".
What it will probably NOT look like, is AI added on top of an existing observability solution or existing observability data, simply because that is what we attempted and failed with AIOPs. It will have to be a full-stack system in which everything is designed around using AI for the explicit goal of performing root cause analysis.
What would this look like in practice?
Full-stack AI-native architecture with data collection, processing, storage, and visualization
An Inferencing solution would have to be vertically integrated — that is, it would have to collect telemetry data, process the data, and own the data pipeline, and the interaction layer with users.
This is important because it would allow the solution to use user interactions to learn and update its data processing and collection mechanisms.
It would also be critical for the Inferencing solution to directly be able to collect the data it needs, in the format it needs, with the context it needs, from the customer environments — to have control over the effectiveness of the root-causing and the user experience.
Adaptive data collection
An Inferencing solution would have to have intelligence embedded into the data collection itself. That means the agent should be able to look at the data streaming in and decide at the moment whether to capture or discard.
Today, all instrumentation agents are "dumb" — they just take a snapshot of all data and ship it, and processing occurs later. This makes sense today because we primarily use code-agents, and we want the agents to be as lightweight as possible and add minimal overhead.
However, with the emergence of technologies like eBPF that allow us to do out-of-band data collection from the kernel with almost zero overhead, it is possible to imagine an intelligent instrumentation agent that actively solves for the data quality that inferencing models would require.
Data processing tuned to specific use-cases
In Inferencing, all data processing techniques would have to be centered around specific use cases — for instance, How do I reliably error type A? And error type B? And so on.
All data processing models would follow the principle of being able to reliably root-cause some types of errors, and slowly increase the type of errors they would identify as the models evolve. This may lead to different data types, data pipelines, and prompts for each type of error. We may have some inferencing platforms that are better at root-causing infrastructure errors, some at security issues, some at code errors, and so on, with each type collecting slightly different data sets, with slightly different data pipelines and a different model framework.
What they will probably not do is "general anomaly detection" and then work backward to see what might have caused the anomaly. This is because the data required to root cause an error is very different from the data required to "identify/spot" an error.
Storage designed for AI
The view of storage in an Inferencing world already looks different from that in a monitoring or observability world. We now have massive data stores for everything that occurred, but in inferencing what we need is just storage of the most relevant and recent data the AI models need to root cause errors reliably. This could involve several practices — storing data in vector DBs for easy clustering and withdrawal, storing only a small portion of success cases and discarding the rest, deduping errors, and, so on.
As a result, the amount of storage required for Inferencing solutions could actually be less than what traditional monitoring and observability solutions needed.
Simpler, more interactive user interface
An Inferencing interface would probably look less like a bunch of dashboards with data, and more like a conversational++ interface that is tuned for development teams. Maybe it has a simple table of prioritized errors that need human attention — you click on each error, and it gives a list of the most likely root causes with a probability of accuracy. It could then have RLHF (Reinforcement Learning from Human Feedback) to have users confirm whether a root cause was identified correctly, so the models would improve performance with time. The possibilities are broad here.
Summary
In summary, there are likely to be sweeping changes in the monitoring and observability space with the recent developments in Gen. AI.
The first wave of solutions are likely to resemble the AIOPs platforms of yore, with a thin Gen. AI wrapper around existing observability data. Incumbents are best positioned to win this wave. This is likely to be akin to Github Copilot - you get a good suggestion about ~10% of the time. However, the true leap forward is probably a couple of years out, with a new class of Inferencing solutions that can accurately root cause errors 80%+ of the time. To be able to do this, they would need to be full-stack and own the data collection, processing, storage, models, and user interactions. We explored some early hypotheses on how Inferencing solutions would differ from existing practices in each part of the stack.